Summary
Most organizations experimenting with artificial intelligence (AI) reach the same inflection point. Access expands, training happens, and teams start using tools. Then productivity stays flat. Outputs require heavy editing. Usage drops back to where it started. Leadership wants to know what went wrong.
The answer is structural. McKinsey and Company research finds that 78% of organizations have adopted AI in at least one business function. Fewer than a third report sustained productivity gains. Access and outcomes are two different problems. Access requires a tool. Outcomes require a work system redesigned to absorb what the tool produces.
This playbook covers six components that close that gap. Each component builds the foundation that the next one requires. Organizations that skip steps rebuild later, usually under pressure that makes the work harder.
Why AI Experimentation Gets Stuck
Experimentation tests whether AI can produce a certain kind of output. Moving from experimentation to adoption requires designing the work around what AI produces. These are different engineering problems.
Teams that experiment with AI test it against tasks in isolation. Organizations that try to scale that experimentation into daily operations often find that the workflow system cannot absorb what AI produces. Outputs arrive faster than the review process can handle. Quality standards were never made explicit, so reviewers apply inconsistent judgment. The team member who understands the tools becomes the bottleneck for everyone else.
Designing AI into an undocumented workflow amplifies its ambiguity. Designing AI into a well-mapped workflow compounds its efficiency. The difference lies entirely in the preparation work done before deployment.
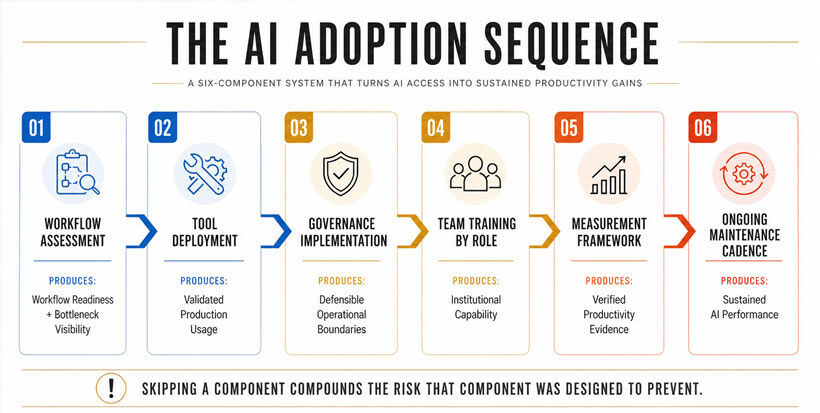
Component One: Workflow Assessment
Mapping the workflow before deploying any tool is the step most organizations skip. The resistance is understandable. Mapping a workflow often reveals it has never been formally documented. It also reveals that different team members execute it differently, or that the real bottleneck sits somewhere other than where leadership assumed.
The assessment produces three outputs. The first is a current-state workflow map for each targeted process, documented at the step level. The second is a failure-point inventory that identifies where the workflow breaks down, slows, or depends on a single person. The third is an AI readiness rating for each workflow on a three-level scale.

A workflow rated Ready has clear inputs, defined quality standards, and structured outputs. A workflow rated Needs Clarity has ambiguous standards or undocumented steps. These need process improvement before AI deployment. A workflow rated Not Appropriate has high variability or judgment requirements that make AI assistance counterproductive at this stage.
The readiness rating determines sequencing. Deploying AI into a workflow that has not cleared the assessment adds speed to a broken process. That creates problems faster, at higher volume.
Component Two: Tool Deployment
Tool selection follows workflow assessment. The specific tool matters far less than the fit. Fit means the tool matches the specific workflow, the specific user, and the quality standard that user is accountable to.
Three questions require specific answers before any tool enters production. The first: what exact workflow problem is this solving, and what does success look like in measurable terms? The second: what does governance look like before deployment, not after? Component Three must be complete before this question has a real answer. The third: what is the baseline measurement, and how will the team verify whether the tool is producing better outcomes?
An organization that cannot answer all three questions should delay deployment until it can. These are the structural conditions that make AI output usable in a real workflow. Without them, outputs are impressive in a demonstration and unreliable in production.
Deployment should include a structured 90-day output quality review. A senior team member reviews a sample of AI outputs against the defined quality standard during those first 90 days. This builds a documented understanding of where the tool performs well and where the review layer requires more human judgment. That understanding becomes part of the institutional record.
Component Three: Governance Implementation
Governance is the set of decisions that allow an organization to deploy AI without creating unexamined exposure. Five decisions require explicit answers before AI tools touch any workflow involving sensitive data, client information, or regulated content.
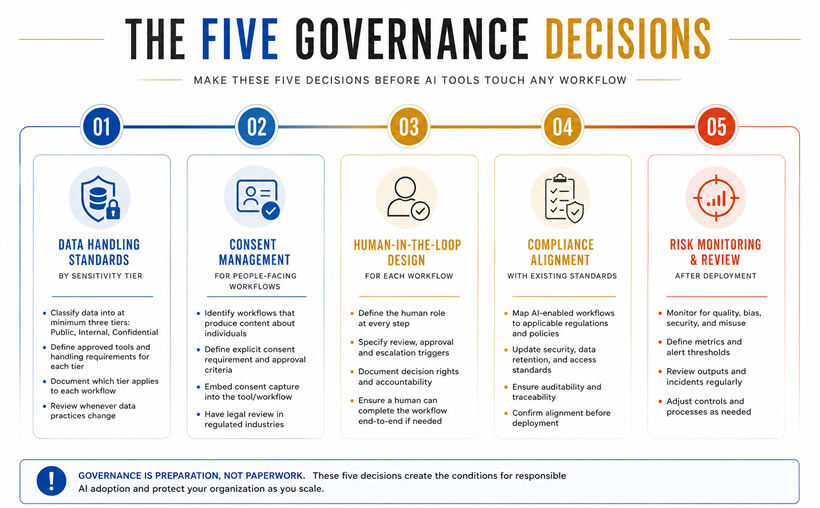
Data handling standards by sensitivity tier. Classify organizational data into at minimum three tiers. Public information is appropriate for any AI tool. Internal information is appropriate for enterprise-licensed tools with security settings configured. Confidential information requires human handling or an approved private model deployment. Document which tier applies to which workflows before deployment. Review that documentation whenever data handling practices change.
Consent management for people-facing workflows. Any workflow producing content about a specific individual requires an explicit consent decision before AI involvement. Testimonials, reference letters, candidate profiles, and client communications all fall into this category. Legal counsel should review this decision in regulated industries. Build the consent architecture into the tool itself. Employees bypass separate consent processes under time pressure, so the architecture must be embedded rather than external.
Human-in-the-loop design for each workflow. Every AI-enabled workflow needs a defined review point. It also needs a quality standard that triggers escalation and a named person who owns the final output. The review requirements differ by workflow type. A marketing campaign draft carries different review requirements than a legal document summary or a candidate evaluation.
Access control by role and function. Role-based access is both a security decision and an adoption decision. Employees who use tools for workflows they were not trained on create cleanup work that undermines confidence in the program.
Output review standards by content category. Define what acceptable output quality looks like for each category of AI output before deployment. This is the standard the 90-day quality review measures against. It is also what team members apply when evaluating their own outputs day-to-day.
Organizations that make these five decisions before deployment build governance that protects the program. Organizations that make these decisions after an incident spend considerably more time and resources reaching the same place. The added difficulty is managing whatever the incident produced while doing so.
Component Four: Team Training by Role
People adopt tools that are demonstrably easier to use than the alternative. Low adoption is often misread as a training deficit. The actual cause is usually a design mismatch. The tool does not fit the specific workflow, the specific user, or the quality standard that the user is held to. Fix the design before adding training.
The right training accelerates adoption. The critical distinction is training for mental models rather than training for tool mechanics.
Team members trained on tool mechanics know how to use the current version of a specific tool. Tool updates and model improvements restart them from scratch. Team members trained on AI mental models understand why AI produces the results it does. They know which task types AI handles well and where human review adds value. They evaluate output quality against a defined standard rather than personal judgment. That understanding carries across tools and model generations.
Role-based training maps specific tools to specific workflows for each function. A sales representative, a content writer, a recruiter, and a finance analyst all use AI differently. Their quality standards and review requirements differ accordingly. Generic training covers no function specifically. Role-based training builds the quality standards directly into the curriculum rather than leaving them as assumed knowledge.
The goal of training is institutional capability. Many organizations build AI capability inside one person and call it an AI program. That person’s absence removes the capability. Their departure takes all the undocumented knowledge with them. Training programs that build institutional capability document the workflows and standards. They distribute understanding across the team and make AI capability an organizational asset. No single person’s presence determines whether the program runs.
Component Five: Measurement Framework
Return on Investment (ROI) from AI requires a before. Establishing baseline measurements before deployment is the only way to demonstrate whether the program is working. It is also the only way to detect when it is failing quietly.

Productivity measurement runs at 30, 60, and 90 days for each AI-enabled workflow. Output quality tracks against the defined standard from Component Three. Every workflow generates three metric types, regardless of its function.
Time metrics track how long each workflow step takes before and after AI deployment. Quality metrics track how often outputs meet the defined standard without requiring significant human revision. Volume metrics track how much work gets completed per person per unit of time.
Tracking platform logins, prompt submissions, and output volume provides an organization with insight into access. Impact measurement requires before and an after measured against the same standard. Organizations that measure activity without establishing baselines cannot prove the program is working or detect when it stops.
The measurement framework also establishes the reassessment trigger. A workflow that shows no measurable improvement by the 90-day mark returns to Component One for reassessment. The cause is usually one of three things. The workflow was not ready for AI deployment. The tool does not fit the workflow. The quality standard was not defined specifically enough to guide the review layer.
Component Six: Ongoing Maintenance Cadence
AI systems require ongoing maintenance to stay effective. ChatGPT Generative Pre-Trained Transformer (GPT) models, Claude models, Gemini models, and Copilot models all update on quarterly or more frequent cycles. Each update changes what the model produces well, how prompts need to be structured, and what the review layer needs to catch. Organizations that treat deployment as a one-time project watch outputs degrade gradually, often without understanding why.
The quarterly maintenance cadence covers three activities. The prompt review assesses whether each production prompt still produces outputs that meet the quality standard, accounting for model changes since the last review. The workflow performance review assesses whether the productivity and quality metrics from Component Five are trending in the right direction. Tool reassessment evaluates whether the current tool still fits the workflow, or whether a newer capability serves it better.
Quarterly is the minimum cadence. Fast-moving periods in AI platform development require more frequent attention. The purpose of maintenance is to sustain the performance of systems the organization has already invested in building.
Sequencing Matters More Than Speed
The organizations achieving sustained AI productivity gains built the work systems correctly, established governance before deployment, and treated maintenance as an ongoing operational responsibility.
The six components are sequential because each one creates the foundation that the next requires. Workflow assessment reveals which processes are ready. Tool deployment builds on that readiness. Governance makes deployment defensible. Training creates the institutional capability that governance protects. Measurement proves the investment and surfaces failures early. Maintenance sustains performance through model changes.
Skipping a component compounds the risk it was designed to prevent. Four skips account for most AI adoption failures, in order of frequency. The first is deploying before workflows are assessed. The second is deploying without governance in place. The third is training for tool mechanics rather than mental models. The fourth is measuring activity rather than outcomes. All four are preventable with the sequencing described in this playbook. All four are preventable with the sequencing described in this playbook.